前一篇文獻比較了透過資料集訓練分辨肉品新鮮度的4種模型。模型訓練的資料集佔了模型訓練很重要的一部份,若是資料來源的影像過於模糊無法辨識,對於模型的最終效能有不良的影響。
此篇文獻為研究人員利用相機解析度在 8 百萬像素到 1,300 萬像素之間的Tecno Camon 15、Infinix Smart 5、LG V50S ThinQ 和三星 S21在迦納(Ghana,位於非洲西部的國家)的真實環境中拍攝的,包括露天市場、肉店和冷藏設施。
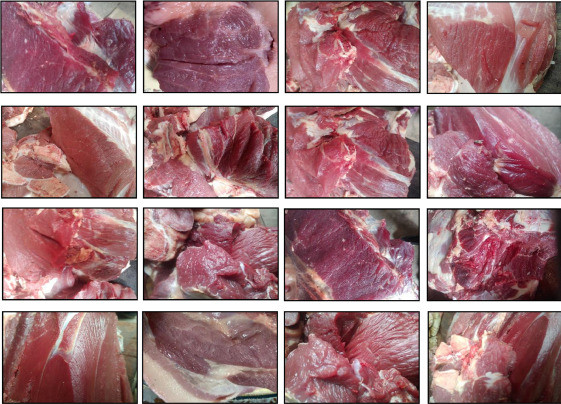
圖一、新鮮牛肉類樣本影像
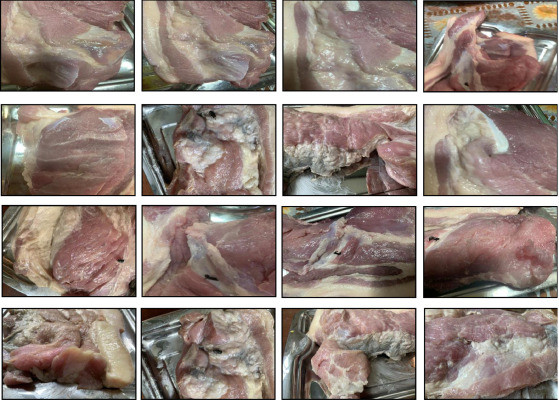
圖二、腐爛牛肉類樣本影像
此資料集包含 11,000 張生牛肉的 RGB 影像,分為新鮮和變質兩個不同的類別。共有 3487 張圖像屬於新鮮類,而 3508 張被標記為變質。其中總共 4005 張增強影像,包括透過翻轉、旋轉和亮度改變生成的 2140 個新鮮樣本和 1865 個變質樣本。增強技術可用於增加資料集的多樣性和機器學習模型的泛化能力。
此一資料集有助於快速、客觀和可擴展地檢測肉類腐敗情況,克服不一致及主觀的人工檢查方法。作為食品安全、農業和公共衛生領域電腦視覺應用的真實參考資料集,可用於訓練和基準測試 CNN、遷移學習模型以及適用於行動裝置的輕量級分類器,對於後續相關領域的模型訓練及研究是一大幫助。
參考文獻:
Gyening, R. M. O. M., Akoto, M. A., & Owusu-Agyemang, K. (2025). MeatScan: An image dataset for machine learning-based classification of fresh and spoiled cow meat. Data in Brief, 62, 112045. https://doi.org/10.1016/j.dib.2025.112045

